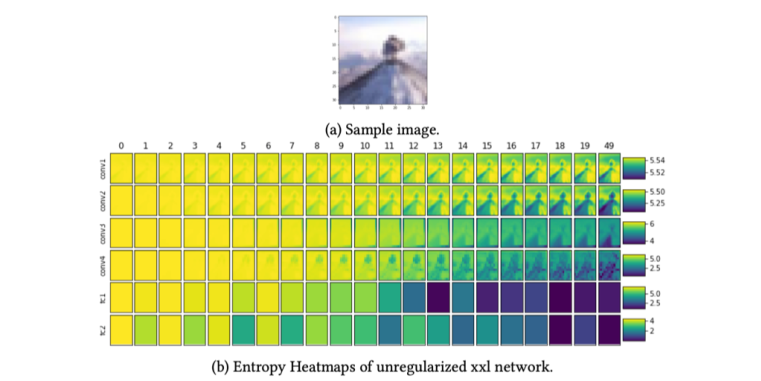
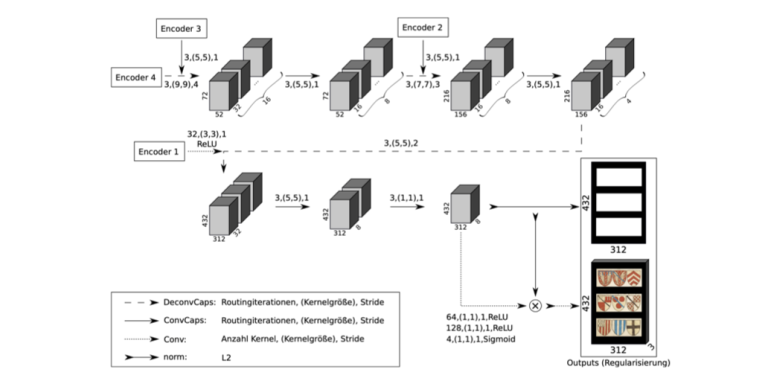
Explainable Deep Learning
Deep neural networks architectures have achieve a remarkable performance in difficult tasks in the recent years. They are able to learn an internal representation of the problem that can surpass human capacity. However, to most extend, this internal representation remains hidden in the architecture and the learned parameters, making this aproach a black box. To be able to understand and explain how this networks will perform to unknown data is still a challenge.
Be developing new per layer visualization methods and analysis tools, partially based in biological approaches, mainly from the field of neurobioloy, we aim to understand how the networks works, and be able to interpret its results. To be able to explain what the network has learned and how it will perform in different scenarios we aim to use network structures with less deepness and with a reduce number of trainable parameters while maintaining the same accuracy. The last is achieved by maximizing the network available capabilities.
The ultimate goal is to create a network architecture that can learn in an unsupervise or semi-supervise manner achieving a good performance. To do that our research is based on three pilar concepts: sparsity, saliency and decorrelation.