
A pipeline for digitizing table-based coin find data from PDF documents
DOI:
https://doi.org/10.17879/ozean-2020-2778Abstract
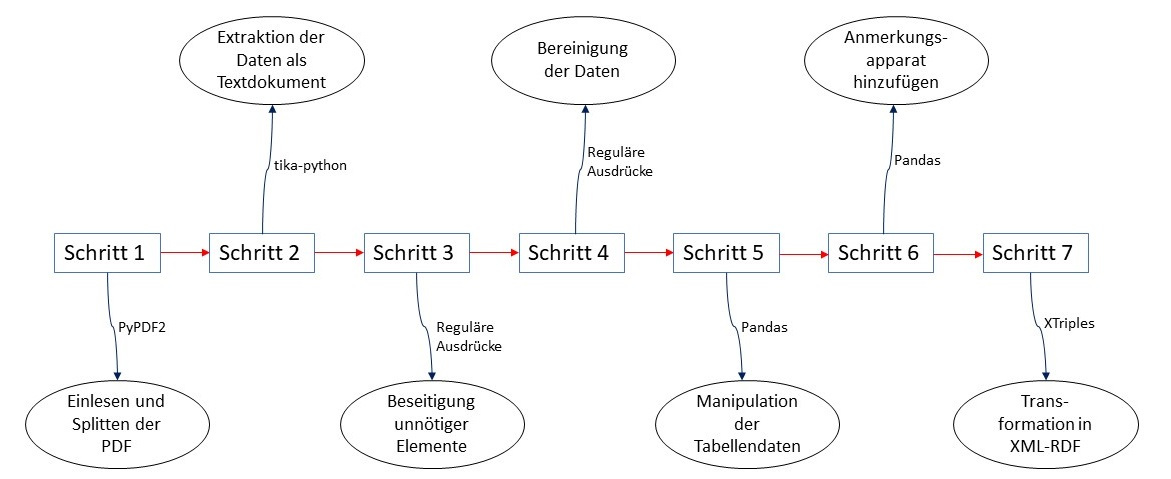
This paper describes a method to extract text-based coin find data and transfer it to RDF. The method was developed as part of a master thesis. It is based on the publications of the project »Die Fundmünzen der Römischen Zeit in Deutschland (FMRD)«. The paper deals with the challenge of such digitisation and then offers a solution based on an example coin complex. This solution represents a pipeline consisting of several scripts, which makes it possible to output the data from a PDF as text, to modify it via the intermediate format CSV and then to output it as RDF.
Downloads
Published
2020-05-09
How to Cite
Kissinger, T. (2020). A pipeline for digitizing table-based coin find data from PDF documents. Online Journal for Ancient Numismatics, 2, 5–19. https://doi.org/10.17879/ozean-2020-2778
Issue
Section
Articles
