A.2: Generative Modelle
Contents
A.2: Generative Modelle#
Statistische Modelle sollen die Wahrscheinlichkeitsverteilungen von möglichen Sequenzen annähern. Als generative Modelle können so Sequenzen entsprechend weiter fortgesetzt werden, dass sie diesen Wahrscheinlichkeiten genügen. Im allgemeinen ist dabei die Wahrscheinlichkeit für das erscheinen eines Symbols / Zustandes in einer Sequenz als abhängig von den vorhergehenden Symbolen angenommen:
Wir haben uns mit der Abfolge von Wortfolgen befasst, für die die Wahrscheinlichkeit für eine Wortfolge gegeben ist als
Dabei können wir die bedingte Wahrscheinlichkeit für ein Wort nach einer vorhergehenden Wortfolge über unseren Count annähern. Im allgemeinen gilt dabei
In n-gram Modellen wird dies weiter angenähert in dem hierbei nicht die vollständige bisherige Wortfolge / Sequenz in der bedingten Wahrscheinlichkeit betrachtet wird, sondern nur die letzten
Als ein Beispiel: Für ein Bigram-Modell nähern wir die Wahrscheinlichkeit für das nächste Wort damit nur in Abhängigkeit des direkt vorhergehenden Wortes an (diese Abhängigkeit nur vom direkt vorgehenden Wort / Zustand wird auch als Markov-Eigenschaft bezeichnet).
Berechnung Wahrscheinlichkeiten in n-grams#
Auch diese Wahrscheinlichkeit können wir direkt aus den Counts für das Auftreten von n-grams bestimmen:
In unserem Beispiel: Zuerst wieder die Tabelle mit counts für Bigrams (für
i |
want |
to |
eat |
chinese |
food |
lunch |
spend |
|
|---|---|---|---|---|---|---|---|---|
i |
5 |
827 |
0 |
9 |
0 |
0 |
0 |
2 |
want |
2 |
0 |
608 |
1 |
6 |
6 |
5 |
1 |
to |
2 |
0 |
4 |
686 |
2 |
0 |
6 |
211 |
eat |
0 |
0 |
2 |
0 |
16 |
2 |
42 |
0 |
chinese |
1 |
0 |
0 |
0 |
0 |
82 |
1 |
0 |
food |
15 |
0 |
15 |
0 |
1 |
4 |
0 |
0 |
lunch |
2 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
spend |
1 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
Dieses können wir entsprechend zu Wahrscheinlichkeiten überführen über
i |
want |
to |
eat |
chinese |
food |
lunch |
spend |
|
|---|---|---|---|---|---|---|---|---|
i |
0.002 |
0.33 |
0 |
0.0036 |
0 |
0 |
0 |
0.00079 |
want |
0.0022 |
0 |
0.66 |
0.0011 |
0.0065 |
0.0065 |
0.0054 |
0.0011 |
to |
0.00083 |
0 |
0.0017 |
0.28 |
0.00083 |
0 |
0.0025 |
0.087 |
eat |
0 |
0 |
0.0027 |
0 |
0.021 |
0.0027 |
0.056 |
0 |
chinese |
0.0063 |
0 |
0 |
0 |
0 |
0.52 |
0.0063 |
0 |
food |
0.014 |
0 |
0.014 |
0 |
0.00092 |
0.0037 |
0 |
0 |
lunch |
0.0059 |
0 |
0 |
0 |
0 |
0.0029 |
0 |
0 |
spend |
0.0036 |
0 |
0.0036 |
0 |
0 |
0 |
0 |
0 |
Für mehr Hintergrund siehe [Jurafsky and Martin, 2009].
Generierung von Text#
Die Wahrscheinlichkeitsverteilungen können als generatives Modell zur Erzeugung von Texten genutzt werden. Dabei wird für eine schon gegebene Sequenz nach möglichen Fortsetzungen gesucht und dann eine wahrscheinliche ausgewählt. Hierbei wollen wir zwei verschiedene Varianten betrachten und dann im nächsten Schritt sollen sie diese implementieren.
Maximum Likelihood#
Ausgehend von der bisherigen Sequenz, wollen wir rausfinden, welches ist das wahrscheinlichste nächste folgende Wort?
Dazu suchen wir in den oben aufgestellten Tabellen den maximalen Eintrag. Z.B. für ein Bigram Modell würden wir die Sequenz beginnend mit “I” fortsetzen mit “want” da die Wahrscheinlichkeit für eine solche Wortfolge maximal wird (mit
Ein solches Verfahren findet Anwendung in ihrem Smartphone und bietet ihnen nach angefangenen Buchstabenfolgen wahrscheinliche Fortsetzungen an.
Samplen über der Wahrscheinlichkeitsverteilung möglicher Wortfortsetzungen#
Die Wahl des wahrscheinlichsten Wortes hat aber den Nachteil, dass so nur sehr stereotype Sätze entstehen (dies können sie zum Beispiel im Smartphone ausprobieren, in dem sie immer mit dem wahrscheinlichsten angebotenen Folgewort ihren Satz weitervervollständigen).
Ein weiterer Ansatz ist es, über die Fortsetzung zu samplen. Beim samplen wird eine zufällige Auswahl getroffen, die aber einer vorgegebenen Wahrscheinlichkeitsverteilung unterliegen soll. Folgewörter mit einer hohen Wahrscheinlichkeit sollen dabei häufiger (bei wiederholter Durchführung) gewählt werden oder mit einer höheren Wahrscheinlichkeit. Dazu übernehmen wir einfach die Wahrscheinlichkeiten der Wortfolge und samplen aus dieser. In dem obigen Beispiel wäre die Wahrscheinlichkeit für “want” als Folgewort also
Ziel von Teilaufgabe A.2#
Generative Modelle liegen auch aktuellen ChatBots wie ChatGPT zugrunde (Generative Pre-trained Transformer). Ziel dieser Aufgabe ist es, das eingeführte n-gram Modell nun zur Erzeugung eines nächsten, wahrscheinlichen Wortes zu nutzen.
Und dies zweitens in die einfache ChatBot-Schleife einzubauen, so dass der ChatBot durch den Nutzer angefangene Sätze vervollständigt bzw. eine Sequenz von
Ziel ist so das grundlegendes Verständnis von generativen Modellen. Und die Umsetzung des statistischen n-grams Modells in unserem ChatBots. Dabei soll dies entsprechend in die vorgegebene Interaktionsschleife eingefügt werden (die nun natürlich sehr einfach ist - diese kann aber gerne erweitert werden).
Grundlegende Struktur#
#include <iostream>
#include "chat_bot.h"
int main(int argc, const char* argv[])
{
giveWelcomeMessage();
std::string userInput;
do {
std::getline(std::cin, userInput);
std::string botAnswer = askChatBotForAnswer( userInput );
std::cout << botAnswer << std::endl << std::endl;
} while (userInput != "");
return 0;
}
#include <iostream>
#include <string>
#include <random>
// Need include for data structure!
// Implements chat_bot.h
#include "chat_bot.h"
// You should preprocess the user input in the same way as in the file ...
#include "read_file.h"
const int PREDICT_LENGTH = 10;
// Implementation of the interface of a chatbot.
void giveWelcomeMessage()
{
std::cout << "Welcome to the n-gram Bot. You start a sentence and I will finish it ... " << std::endl;
}
// This function takes a map of strings and probabilities and
// returns the string with the highest probability.
std::string returnMostProbableMapEntry( const YOUR_DATA_STRUCT& probabilities ) {
std::string max_ngram;
// Find the entry with highest probability (or count).
return std::string(max_ngram);
}
// This function takes a map of strings and probabilities and returns a randomly chosen string
std::string sampleFromNGramProbabilities(const YOUR_DATA_STRUCT& probabilities) {
// Create a random number generator
std::random_device rd;
std::mt19937 gen(rd());
// You will have to build up a representation that is easy to sample
// and somehow relates to the entries.
return std::string("42");
}
// Call to produce answer - i.e. a sequence of #PREDICT_LENGTH words
std::string askChatBotForAnswer( const YOUR_DATA_STRUCT& probabilities, const std::string& userInput ) {
std::string currentToken, returnSentence;
// Take last word from user input;
// preprocess the word (analog as in read_file);
// Iterate over: Predict next word / sample next word;
// Return sentence.
return returnSentence;
}
CXX := c++
CXXFLAGS := -Wall -Werror -std=c++20
# Contain path for any includes (headers)
INCLUDES := -I./include
# Contains libraries we need to (-L is directory search path, -l is lib)
#LDFLAGS = -L/usr/local/lib -L/opt/homebrew/lib
#LDLIBS = -lcurl -lssl -lcrypto
SRCDIR := ./src
NGRAMBOT_OBS = read_file.o count_ngram.o ngram_bot.o main_ngrambot.o
ngrambot: $(NGRAMBOT_OBS)
$(CXX) $^ -o $@ $(LDLIBS)
%.o: $(SRCDIR)/%.cpp
$(CXX) $(INCLUDES) $(CXXFLAGS) -c $^ -o $@
make ngrambot
./ngrambot --input data/sample.txt
Anweisungen
In der vorherigen Aufgabe haben sie counts für n-grams erstellt. Setzen sie diese nun in Wahrscheinlichkeiten um.
Implementieren sie nun eine Funktion, die für eine vorgegebene Wortfolge (als Prompt) das wahrscheinlichste nächste Wort zurückgibt (basierend auf den Wahrscheinlichkeiten über den n-grams, also hier mindestens den Bigrams und dabei dann nur die letzten
Implementieren sie dann eine Funktion, die analog ausgehend von der bisher vorgegebenen Wortfolge dann ein nächstes Wort sampled (siehe Erklärung oben).
Passen sie so die Verarbeitung der Interaktionsschleife auch an, dass hier aufgefordert wird einen Satzanfang zu geben, der dann als Prompt ihrer generierenden Funktion mit übergeben wird. Dabei müssen sie auch die Vorverarbeitung auf diesem entsprechenden Prompt durchführen, analog zu
read_file.cpp.Für eine generierende Funktion: Führen sie eine Funktion ein, die als einen Parameter nutzt, wieviele Worte in Folge generiert werden sollen und die die bereits implementierte Funktion nutzt.
Erweitern sie die samplende Funktion auf trigrams.
Zum samplen müssen sie eine random-Funktion nutzen. Allgemein können sie dies realisieren, indem sie über eine bekannte Wahrscheinlichkeitsverteilung samplen (siehe zum Beispiel STL uniform_real_distribution) oder zuerst dies in eine diskrete Verteilung (diskret durch die Zuordnung von Folgewörtern) überführen und aus dieser samplen: STL discrete_distribution.
Tipp / Erklärung zum samplen - hier öffnen
Zum samplen müssen sie eine random-Funktion nutzen. Allgemein können sie dies realisieren, indem sie über eine bekannte Wahrscheinlichkeitsverteilung samplen (siehe zum Beispiel STL uniform_real_distribution.
Von dieser Zufallszahl (

Fig. 3 Aufteilung der Wahrscheinlichkeiten für mögliche Folgewörter auf das Intervall
Alternativ können sie auch über die Gesamtanzahl (die bisherigen counts) von Folgewörtern STL:uniform_int_distribution samplen, die sich daraus ergebende Funktion ist dann natürlich nicht so allgemein.
Inweiweit wirkt sich die gewählte Speicherstruktur als Repräsentation für die n-grams nun auf die Generierung aus? Welche Strukturierung ist hier besser geeignet für die Berechnung der Wahrscheinlichkeiten?
Wenn sie hierbei die Laufzeit verschiedener Repräsentationen betrachten wollen, können sie dies durch Einbindung von chrono gut empirisch testen:
#include <chrono>
// ...
std::chrono::steady_clock::time_point begin = std::chrono::steady_clock::now();
// ... do some function that should be timed
std::chrono::steady_clock::time_point end = std::chrono::steady_clock::now();
std::cout << "Time difference = " << std::chrono::duration_cast<std::chrono::microseconds>(end - begin).count() << "[µs]" << std::endl;
Beispielergebnis#
Als ein Beispielergebnis sind hier einmal vergleichend generierte Texte von n-grams verschiedener Tiefe angegeben.

Fig. 4 Beispiel generierter Texte für verschiedene n-gram Tiefen. Sätze wurden zufällig generieret basierend auf Wahrscheinlichkeiten für n-grams über dem Wall Street Journal Korpus. Aus [Jurafsky and Martin, 2009].#
Weiterführende Fragen, Diskussion#
n-gram Modelle sind einfache Modelle, die statistische Zusammenhänge über Wortfolgen modellieren können. Sie können so gut zur Klassifikation und Erkennung von Autoren genutzt werden. Oder, wie hier umgesetzt, zur Generierung von Texten. In den Beispielen oben fällt auf, dass letztlich dabei mindestens Bigram-Modelle genutzt werden sollten. Trigram-Modelle liefern zumindest über kurze Beispiele noch halbwegs lesbaren Text. In der Generierung liefern höhere
Weiterführende Fragen:
Überlegen sie einmal, warum jedoch in der Praxis letztlich fast ausschliesslich
Für größere
Welche Art von Beziehungen können nicht gut durch n-grams abgebildet werden? Überlegen sie hier einen alternativen Ansatz oder eine Erweiterung.
n-grams bilden nur Wahrscheinlichkeiten für direkt aufeinanderfolgende Wörter ab. Sie erlauben es jedoch nicht, weitreichendere Verbindungen und Relationen widerzugeben. Daher sind solche Modelle inhärent schlecht zum Beispiel semantische und inhaltsbezogene Verbindungen zu erfassen (und können dies nicht über mehrere Sätze hinweg). Solche Relationen sind häufig aber schon innerhalb einzelner Sätze bedeutsam, wenn es um Beziehungen zwischen Prädikat und Subjekt geht oder um mögliche Objekte, da diese durchaus weit von einander getrennt vorkommen können. Einen Ansatz bieten hier skip gram Modelle, die neben der direkten Nachbarschaft auch Beziehungen unter Auslassungen einzelner Worte mit betrachten und modellieren (siehe https://www.notsobigdatablog.com/2019/01/02/what-is-a-skipgram/).
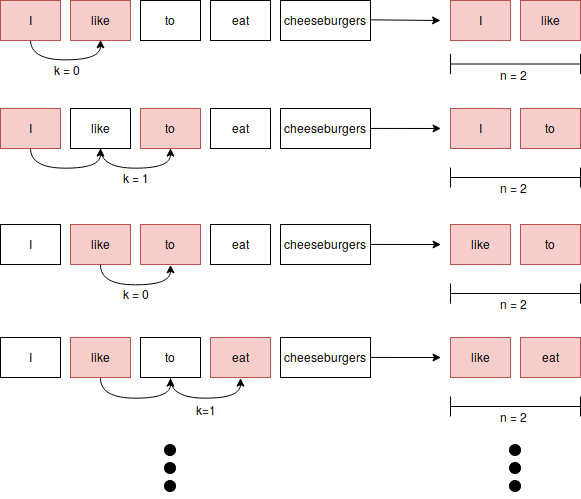
Fig. 5 Beispiel für den Aufbau von einem skip gram Modell mit
Referenzen#
Allgemein zu generativen Modellen, siehe zum Beispiel eine Einführung in Google’s Developer Tutorials oder
(ältere) Beispiele von OpenAI.
Weiterführend zu n-gram Modellen zur Textgenerierung
- 1(1,2,3)
Daniel Jurafsky and James H. Martin. N-grams. In Speech and Language Processing, chapter 4. Prentice-Hall, Englewood Cliffs, NJ, 2009.
- 2
Michael Struwig. What is a skipgram? Blogpost., 2019. URL: https://www.notsobigdatablog.com/2019/01/02/what-is-a-skipgram/.